Flask Database Migration
As applications change the database may need to evolve with them. I want to investigate how this works in Flask before building more of the application.

As applications change and grow the database may need to evolve with them. I want to investigate how this works in Flask before building too much more of the application.
To add functionality to an application it is often necessary to modify the table structure. Flask has an add-on, flask-migrate, which helps with this process, allowing you to keep the database in step with application changes.
Care is required to avoid dropping user data — you cannot simply drop and recreate all tables in a production environment. A migration script is required that will move the database to the new structure in such a way that the data integrity is maintained.
We are also going to add a user table that will store a nickname for anyone using the application. I am choosing not to worry about authentication at the moment.
When a group is created it will be associated with a user using the foreign key join into the new table. Here’s a simple UML for the structure.
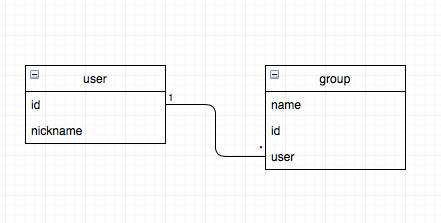
Flask Migrate
Flask-migrate uses Alembic to manage database migrations. You can install it and its dependencies with the command pip install flask-migrate from the activated virtualenv.
There are a set of commands to use to run the migrations, all using the flask db command to start them. Use the option --help to see all the commands.
To allow the add-on to interrogate the database, we need to add code to our application. This will give it a handle to the application and the database objects. It will only be used when one of the flask db commands is issued.
from flask_migrate import Migrate
...
migrate = Migrate(app, db)
The next thing to do is to initialise the migration with flask db init, note that I need to add the FLASK_APP environment variable to the start of the command.
$ FLASK_APP=run.py flask db init
Creating directory ../migrations ... done
Creating directory ../migrations/versions ... done
Generating ../migrations/script.py.mako ... done
Generating ../migrations/env.py ... done
Generating ../migrations/README ... done
Generating ../migrations/alembic.ini ... done
Please edit configuration/connection/logging settings in '../migrations/alembic.ini' before proceeding.
As shown in the output, a new migrations folder is created with various files in it. Each time a new version is created it will be stored in versions folder within this structure. It is a good idea to keep this in source control and commit changes to the model with the migration script associated.
You can change some of the settings in the alembic.ini file. The default logging settings are to output to the console, which is fine for the purpose of this post. We will configure file logging at a later stage. For now we will leave this file and simply add it to source control.
Note also that a new table is added to the database called alembic_versions which is there to track what scripts have been applied. There will be no rows added until an upgrade is performed. It contains a single field to contain the version.
By default this will be a hash, but it is also configurable to be human readable. If you edit the file name, remember to change the revision variable in the generated file. Proably best to stick with the hash.
The next step is to make changes to the model. In this case I want to add a new table called user and add a foreign key column to the group table to reference the user. First the new table:
class User(db.Model):
"""A user that can create groups and issues for estimation"""
id = db.Column(db.Integer, primary_key=True)
nickname = db.Column(db.String(32), nullable=False)
def __init__(self, nickname):
self.nickname = nickname
def __repr__(self):
return self.nickname
Within the group class:
user = db.Column(db.Integer, db.ForeignKey('user.id'), nullable=False)
Once done, the next step is to run the migrate command. Alembic looks at the models in the application, compares it to the database, and generates a set of commands that bring the database up to the same state as the model and another set to downgrade the database back to a previous state.
FLASK_APP=run.py flask db migrate
Before running the migration there are a few things that should be considered. Alembic is not going to be correct under every circumstance and mistakes are common. A failed migration can be difficult to recover from.
Firstly, check the code. It may be obvious that something is wrong. Alembic generates two functions: upgrade() and downgrade() which allow you to move forward and back through versions.

Note that you have to take care that the data in your database is protected. An upgrade followed by a downgrade may cause lost data if not done correctly.
The second thing you should to is to back up the database. I am using SQLite in development, so this is as easy as copying the file with cp data.sqlite data.sqlite.bak so that I can restore it if I make a mistake.
The upgrade script that I got was as following:
def upgrade():
# ### commands auto generated by Alembic - please adjust! ###
op.create_table('user',
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('nickname', sa.String(length=32), nullable=True),
sa.PrimaryKeyConstraint('id')
)
op.add_column('group', sa.Column('user', sa.Integer(), nullable=False))
op.create_foreign_key(None, 'group', 'user', ['user'], ['id'])
# ### end Alembic commands ###
I can see an issue with this immediately. The addition of a foreign key will not be possible as I have data in the group table already. So I am going to need to make some sort of change before I can use this script.
The downgrade function is straightforward. It simply removes the foreign key constraint and drops both the column and the table.
def downgrade():
# ### commands auto generated by Alembic - please adjust! ###
op.drop_constraint(None, 'group', type_='foreignkey')
op.drop_column('group', 'user')
op.drop_table('user')
# ### end Alembic commands ###
Note that no database changes will have been made at this point. All we have done is to create some scripts that will be applied to the database through SQLalchemy.
Upgrading
Even though I know it won’t work, I want to see the process fail. This will help to show the problems with changing the database — it can be left in a bad state if the migration script fails.
To run the upgrade, run FLASK_APP=run.py flask db upgrade. As expected, this failed with the following error. The migration succeeded in adding the user table but not the new column. No new version is added to the alembic_versions table.
Can't have a null foreign key reference:
Cannot add a NOT NULL column with default value NULL [SQL: 'ALTER TABLE "group" ADD COLUMN user INTEGER NOT NULL'] (Background on this error at: http://sqlalche.me/e/e3q8)
I cannot recover the original state without either using SQL statements to drop the new table or restoring from backup. Running upgrade() again will fail as the table exists and downgrade() will do nothing as alembic does not have a version to downgrade from.
I had backed my development database, so it was easy to get back to where I started from, however, with the changes only half-applied, it takes a bit of analysis to see what remedial action is required. This was a small change, but consider what would happen with a larger failure at migration stage. It would be difficult to reverse the changes; restoring from backup seems like the quickest choice.
The solution to the upgrade problem appeared straightforward to me at first. I should change the function so that the new column is created as nullable=True and without a foreign key constraint. I can then update all rows to some default value before making it not null and adding the foreign key constraint.
Unfortunately, I found that while this is possible in most databases, it is not in SQLite, which has limited the things you can do with an alter table statements.
It seems the better option would be to rename the existing table and create it again with the constraint on, but no rows initially. Then insert all the rows from the renamed table before dropping the it.
When I created my Group class, I forgot that this is a reserved word in SQL. My table is created in the database with quotation marks as "group". It seems like a good time to fix this by setting the name of the table to something different explicitly in the code.
SQLAlchemy has its straightforward way of deriving table names from class names that will be useful for most purposes, however, sometime we will not like the choices it uses. So it is good to know you can alter the default choice for both the table and the column names. Adding this field to the model will set the name and avoid clashing with the reserved word:
__tablename__ = 'estimation_group'
I need to create a default user so that I can associate them with the existing groups in my database.
default = User('default')
db.session.add(default)
db.session.commit()
# query to load id
default = User.query.first()
default_id = default.id
I found, after experimenting, that the id was not set in the object after committing it. I had to re-query the row to get this back. I could have just accepted that it was going to be the first serial in the table, the integer one.
I do not strictly have to do a rename first as I am creating a new table with a corrected name, but adding it here to show how to change table structure in general:
op.rename_table('group', 'old_group')
To create the table from scratch I used this command, which I got by running the migration on an empty database.
op.create_table('estimation_group',
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('name', sa.String(length=32), nullable=True),
sa.Column('user', sa.Integer(), nullable=False),
sa.ForeignKeyConstraint(['user'], ['user.id'], ),
sa.PrimaryKeyConstraint('id')
)
Inserting the old data can be done with the execute command and a standard insert statement.
op.execute('INSERT INTO estimation_group (name,user) SELECT name, {} FROM old_group'.format(default_id))
In order to allow upgrading and downgrading of the database between stages, I also have to modify the downgrade function. That means recreating the old group table, inserting the data from the new one (less user id), and then dropping the new tables. Here is what it looks like:
def downgrade():
# ### commands auto generated by Alembic - please adjust! ###
op.create_table('group',
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('name', sa.String(length=32), nullable=True),
sa.PrimaryKeyConstraint('id')
)
# Insert rows from the older version of the tabl
op.execute('INSERT INTO "group" (name) SELECT name FROM estimation_group')
op.drop_table('estimation_group')
op.drop_table('user')
# ### end Alembic commands ###
Using the above code I was able to upgrade and downgrade my database with no further issues. I checked the content at each stage to ensure all rows were accounted for. See using sqlite3 below
Problems and Troubleshooting
Here are a couple of things that I learned along the way while going through this migration. This is only part one of the change, I still have to apply the changes to the MySql database that I have used on my docker-compose set of containers that are representing production.
Using sqlite3 to examine the development database
I found it tricky to get the changes working correctly against the SQLite database I am using. In order to debug some of the issues, I used the sqlite3 application that is available on Mac OSx. Simply point it at your database file:
$ sqlite3 data.sqlite
SQLite version 3.19.3 2017-06-27 16:48:08
Enter ".help" for usage hints.
sqlite> .tables
alembic_version group
sqlite> select * from alembic_version;
sqlite>
You can see above that when I ran this the database was in the original, pre-migration state and that there were no versions in the database. You can see what tables are there as shown above, and even generate the entire schema with the .schema command. For example, you can see the SQL required to create the alembic_version, which is:
CREATE TABLE alembic_version (
version_num VARCHAR(32) NOT NULL,
CONSTRAINT alembic_version_pkc PRIMARY KEY (version_num)
);
To exit use Ctrl-C or .exit. Using Ctrl-Z will return to the terminal and leave sqlite3 running. You can return to it with the command to bring it to the foreground: fg.
Re-running the migration
Perhaps you have run already created the migration script but have had to go back and make additional changes. It may be a good idea to delete any uncommitted scripts and generate a new one that composes all the changes.
Before doing so you should delete or move the uncommitted script out of the migrations/versions/ folder. Alembic can tell if there is a script there that has not been applied.
If you have already upgraded the database, make sure to downgrade first before re-running the migration.
Be sure to check the generated script. If you had to make changes to the original, then it is likely that you will have to make the same changes and more to the existing one.
How does Alembic know what version to run
As you make further changes to the database, you will end up with a number of scripts that need to be applied to a database so that it matches the code that is running against it. Alembic stores the versions that have been applied to the database inside the database.
Once you run the migration, a new table, alembic_version, is created but it has no rows to begin with. As you run upgrades, it will add new rows in here to keep track of the latest version applied.
It scans the migrations/versions/ folder, looking for scripts that have not yet been applied to the database, and can select those that are required. To display the current version of the database, run flask db current.
There are other commands available, such as merging two revisions, stamping a revions as ”don’t run”, seeing a history of the changes to the database. For more information run flask db --help.
Summary
Here is a summary of what I learned.
- Be careful with model class names. Do not use SQL reserved words
- Back up the database before migrating
- Check the script generated by Alembic carefully; it usually requires some changes
- Test the migration in a copy of production before running it there. A MySql database is significantly and subtly different from Sqlite.
Next up will be a post about how I got on with applying these changes to the MySql database running on my docker-compose servers.